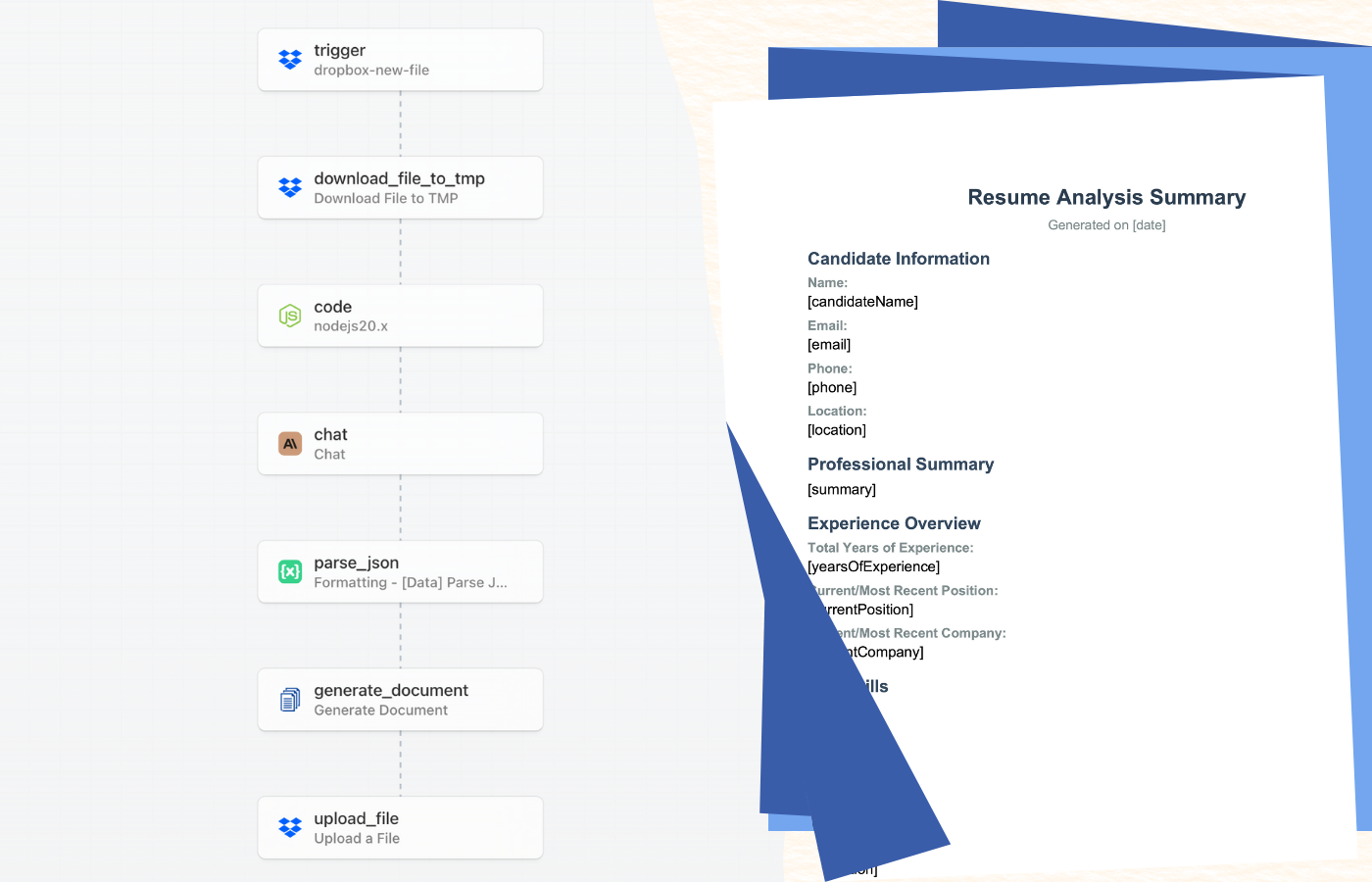
Introduction
Le tri des CV est l’une des tâches les plus chronophages du processus de recrutement. Les équipes RH passent souvent des heures à examiner les CV pour en extraire les informations clés, évaluer les candidats et préparer des synthèses pour les responsables du recrutement. Dans ce tutoriel, nous allons créer un analyseur de CV automatisé qui se charge de ce travail pour vous, en combinant la puissance de l’automatisation de workflows de Pipedream, l’analyse intelligente de Claude AI, et la génération de PDF professionnels de DocuGenerate.
Le workflow s’exécute automatiquement chaque fois qu’un nouveau CV est ajouté à un dossier Dropbox. Il extrait le texte du CV, utilise Claude pour analyser l’expérience et les qualifications du candidat, génère une synthèse structurée avec les points clés, et crée un rapport PDF professionnel que votre équipe de recrutement peut consulter immédiatement. L’ensemble du processus ne prend que quelques secondes et ne nécessite aucune intervention manuelle.
Cette approche est particulièrement précieuse pour les organisations qui doivent traiter rapidement de nombreux CV tout en maintenant une cohérence dans l’évaluation des candidats. En standardisant le format d’analyse et en exploitant l’IA pour en extraire les points clés, vous pouvez consacrer votre temps à l’entretien des candidats les plus prometteurs plutôt qu’à passer des heures sur le tri initial.
Comprendre le Workflow
Le workflow complet se compose de sept étapes interconnectées qui transforment ensemble un CV brut en un rapport d’analyse structuré. Voici comment le processus se déroule de bout en bout :
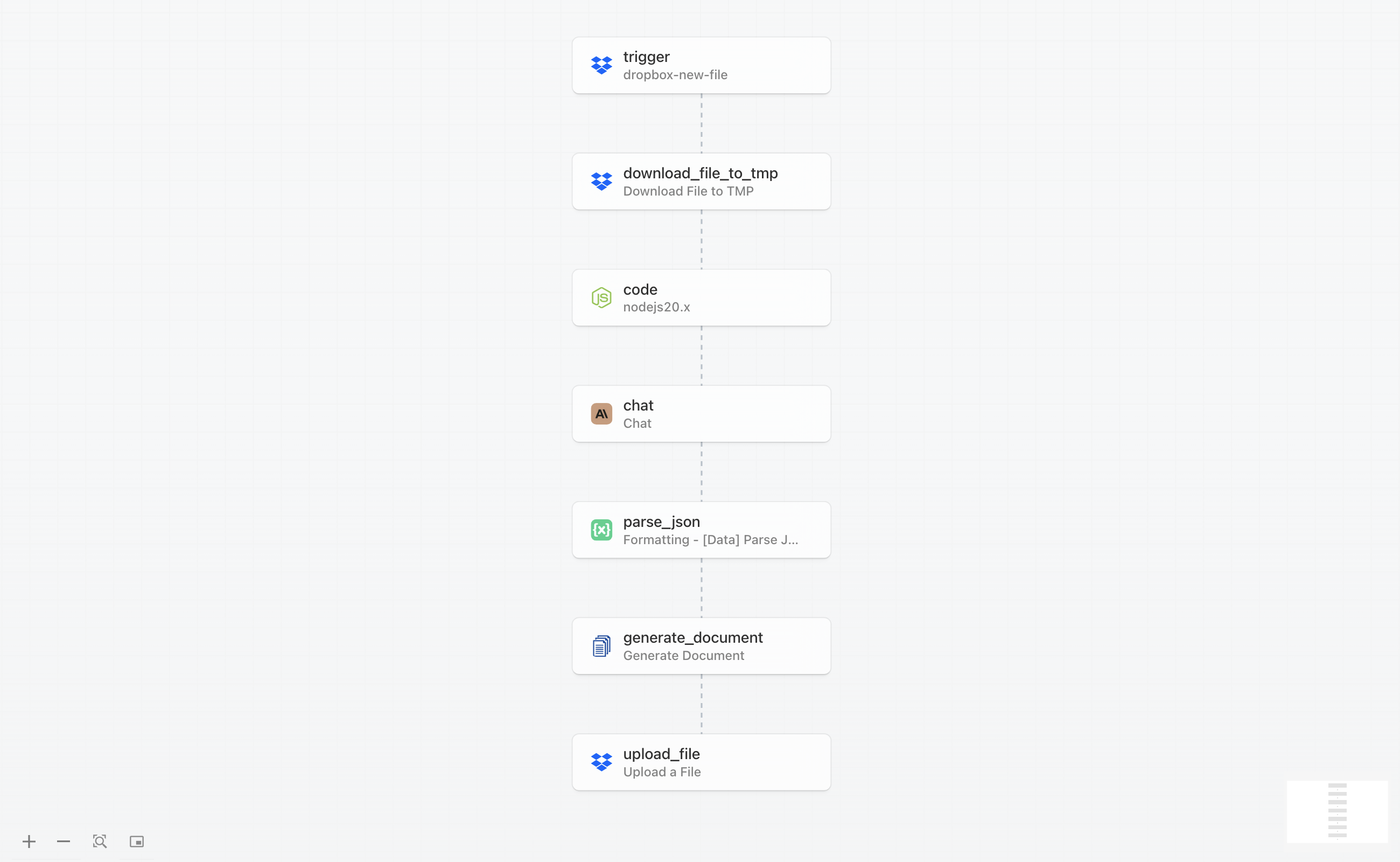
Le workflow commence lorsque vous téléversez un CV dans un dossier Dropbox surveillé. Pipedream détecte le nouveau fichier, le télécharge, et extrait le contenu textuel du PDF. Ce texte est ensuite envoyé à Claude AI avec des instructions précises pour analyser le CV et en extraire les informations clés telles que l’expérience professionnelle, les compétences, la formation et les réalisations notables. Claude renvoie une réponse JSON structurée contenant toutes les données extraites.
Les données JSON sont ensuite transmises à DocuGenerate, avec un modèle préconçu, pour générer une synthèse PDF professionnelle. Une fois le document créé, il est automatiquement renvoyé vers Dropbox dans un dossier désigné où votre équipe de recrutement peut y accéder. L’ensemble du processus se termine en moins d’une minute, et vous pouvez traiter plusieurs CV simultanément en les téléversant simplement dans le dossier déclencheur.
Configurer le Modèle de Document
Avant de créer le workflow Pipedream, nous devons créer un modèle qui mettra en forme nos rapports d’analyse de CV. Le modèle utilise la syntaxe des balises de fusion de DocuGenerate pour définir où les données de l’analyse de Claude doivent apparaître dans le document final. Cela garantit que chaque synthèse de candidat suit un format cohérent et professionnel.
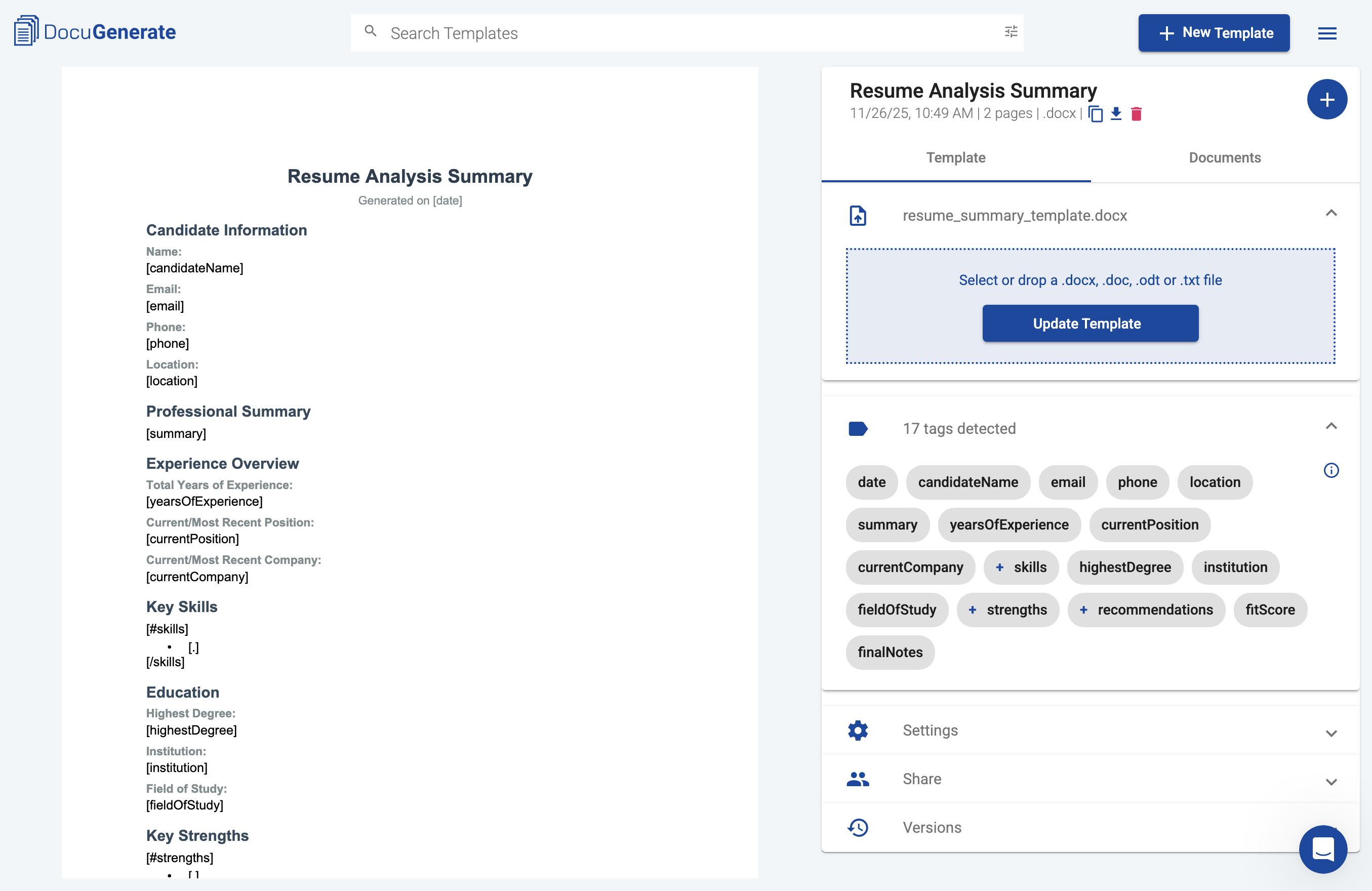
Le modèle comprend des sections pour les informations du candidat (nom, e-mail, téléphone, localisation), une synthèse professionnelle, un aperçu de l’expérience, les compétences clés, la formation, les points forts, des recommandations d’entretien, et une évaluation globale avec un score d’adéquation. Certaines sections comme les compétences, les points forts et les recommandations utilisent la syntaxe de liste pour afficher plusieurs éléments à partir de tableaux dans les données. Par exemple, la section des compétences utilise [#skills] pour démarrer la boucle, [.] pour afficher chaque compétence sous forme de puce, et [/skills] pour terminer la boucle.
Vous pouvez télécharger le modèle complet et le téléverser sur votre compte DocuGenerate. Une fois téléversé, notez le nom ou l’ID du modèle, car vous en aurez besoin lors de la configuration de l’étape de génération de document dans le workflow. Le modèle étant prêt, nous pouvons maintenant créer le workflow Pipedream qui automatisera l’ensemble du processus d’analyse.
Configurer le Déclencheur Dropbox
Le workflow démarre avec un déclencheur Dropbox qui surveille un dossier spécifique pour détecter de nouveaux fichiers. Ce déclencheur est le point d’entrée qui active toute l’automatisation chaque fois qu’un CV est téléversé. Pour configurer ce déclencheur, vous devrez connecter votre compte Dropbox à Pipedream et spécifier le dossier à surveiller.
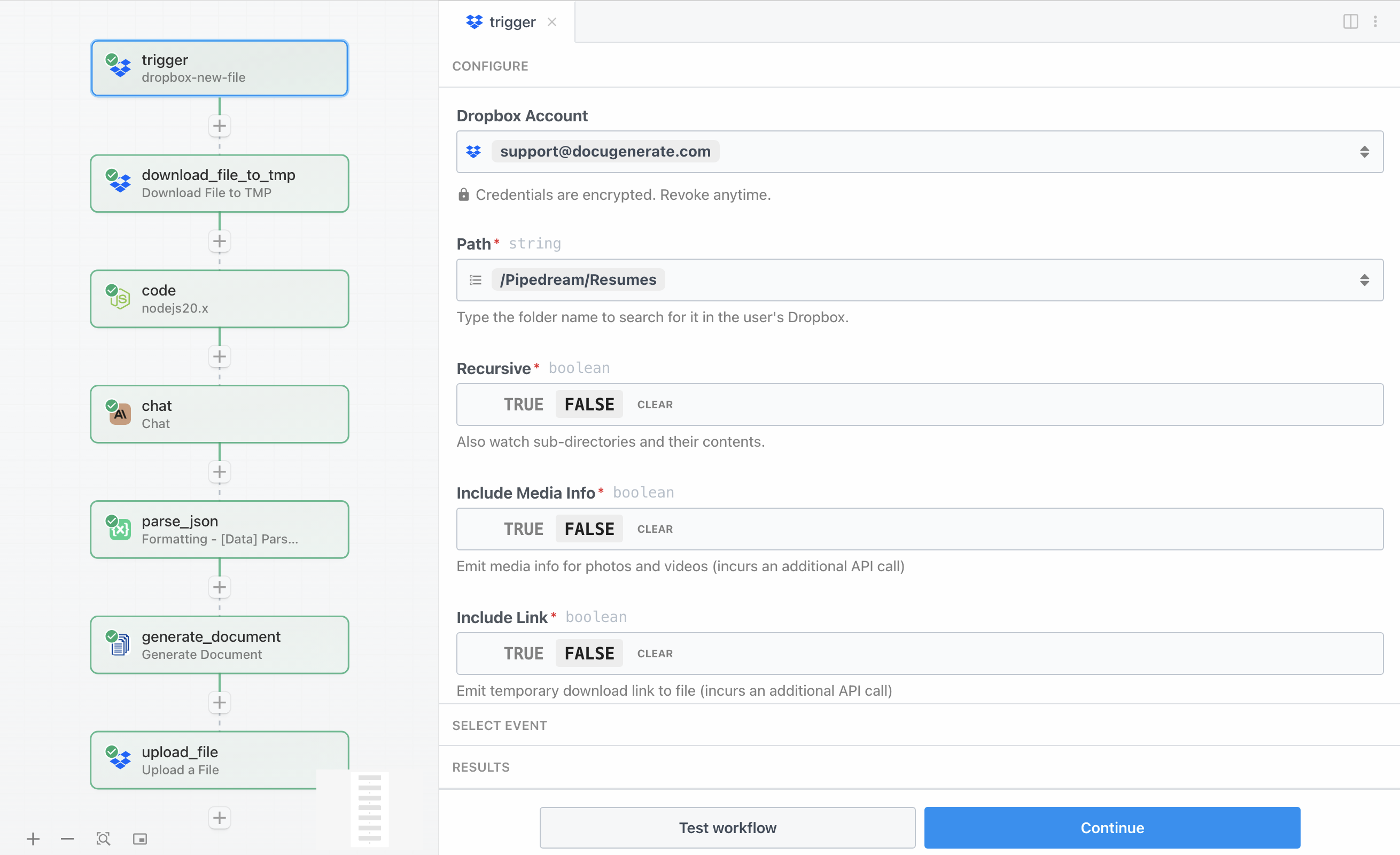
Pour ce tutoriel, nous surveillons un dossier appelé /Pipedream/Resumes. Lorsque vous testez le déclencheur avec un CV d’exemple, vous constaterez qu’il renvoie des métadonnées sur le fichier, notamment le nom de fichier, le chemin, la taille et les dates de modification. Cependant, il est important de noter que le déclencheur fournit uniquement ces métadonnées, et non le contenu réel du fichier. C’est pourquoi nous avons besoin d’une étape distincte pour télécharger le fichier, que nous configurerons dans la section suivante.
Le déclencheur s’active immédiatement lorsqu’un nouveau fichier est détecté, ce qui rend le workflow réactif à vos besoins de recrutement. Vous pouvez téléverser des CV tout au long de la journée, et chacun sera traité automatiquement sans aucune intervention manuelle. Ce traitement en temps réel garantit que les synthèses de candidats sont disponibles pour votre équipe le plus rapidement possible.
Télécharger le Fichier de CV
Une fois que le déclencheur détecte un nouveau fichier, nous devons réellement télécharger son contenu avant de pouvoir en extraire le texte. L’action Download File to TMP récupère le CV depuis Dropbox et l’enregistre dans le stockage temporaire de Pipedream, où les étapes suivantes peuvent y accéder.
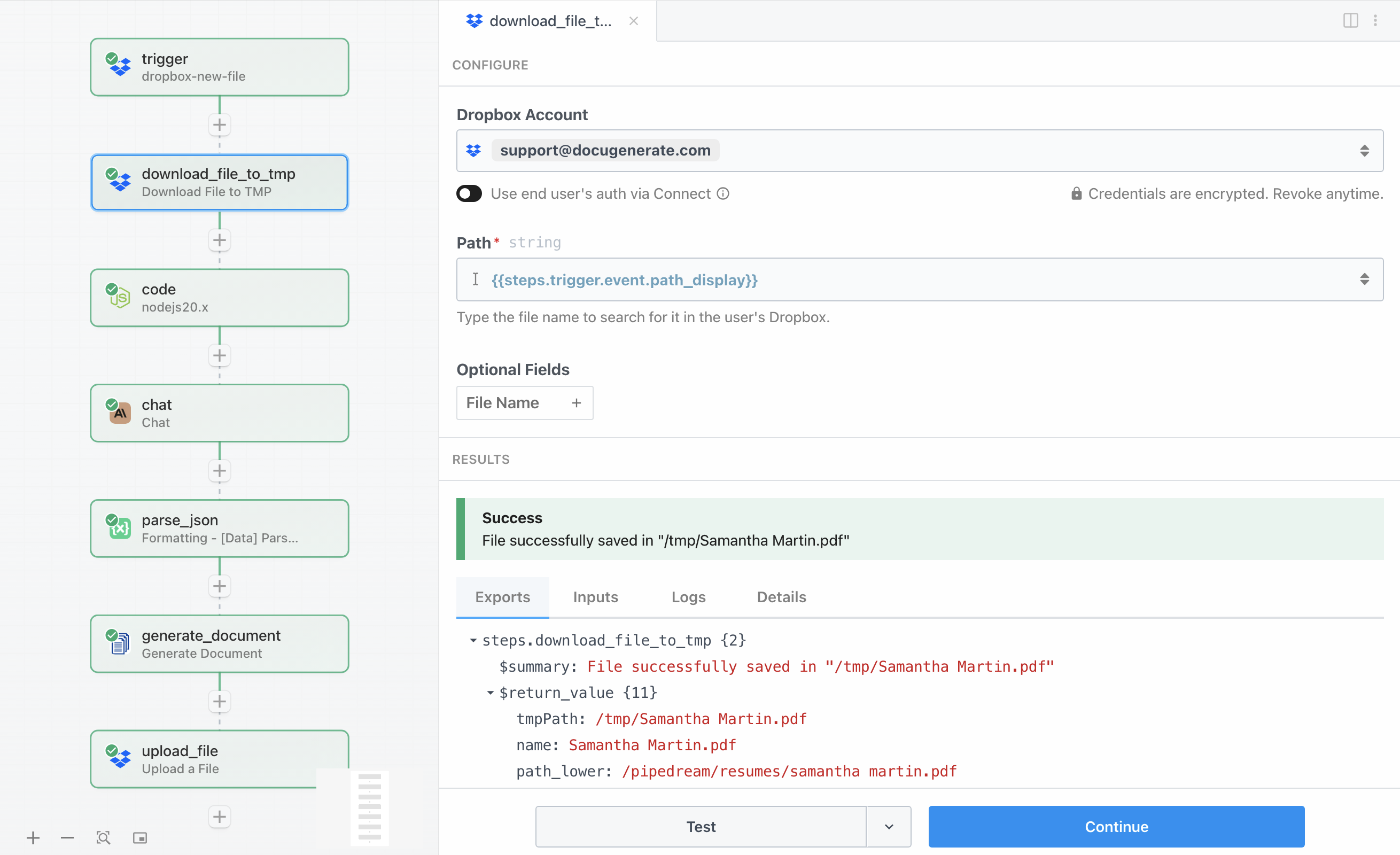
La configuration est simple. Le paramètre Path utilise {{steps.trigger.event.path_display}} pour référencer le chemin de fichier capturé par le déclencheur. Cette action télécharge le fichier et renvoie un objet contenant le chemin de fichier temporaire dans la propriété tmpPath. Le fichier reste dans le stockage temporaire tout au long de l’exécution du workflow, ce qui est idéal pour le traiter puis l’éliminer une fois le workflow terminé.
Le fichier téléchargé est maintenant prêt pour l’extraction de texte. Le chemin de fichier temporaire sera utilisé à l’étape suivante pour lire le contenu du PDF et le convertir en texte que Claude pourra analyser.
Une fois le CV téléchargé dans le stockage temporaire, nous devons maintenant en extraire le contenu textuel du fichier PDF. Cette étape utilise un bloc de code Node.js avec la bibliothèque pdf-parse pour lire le PDF et le convertir en texte brut que Claude pourra analyser.
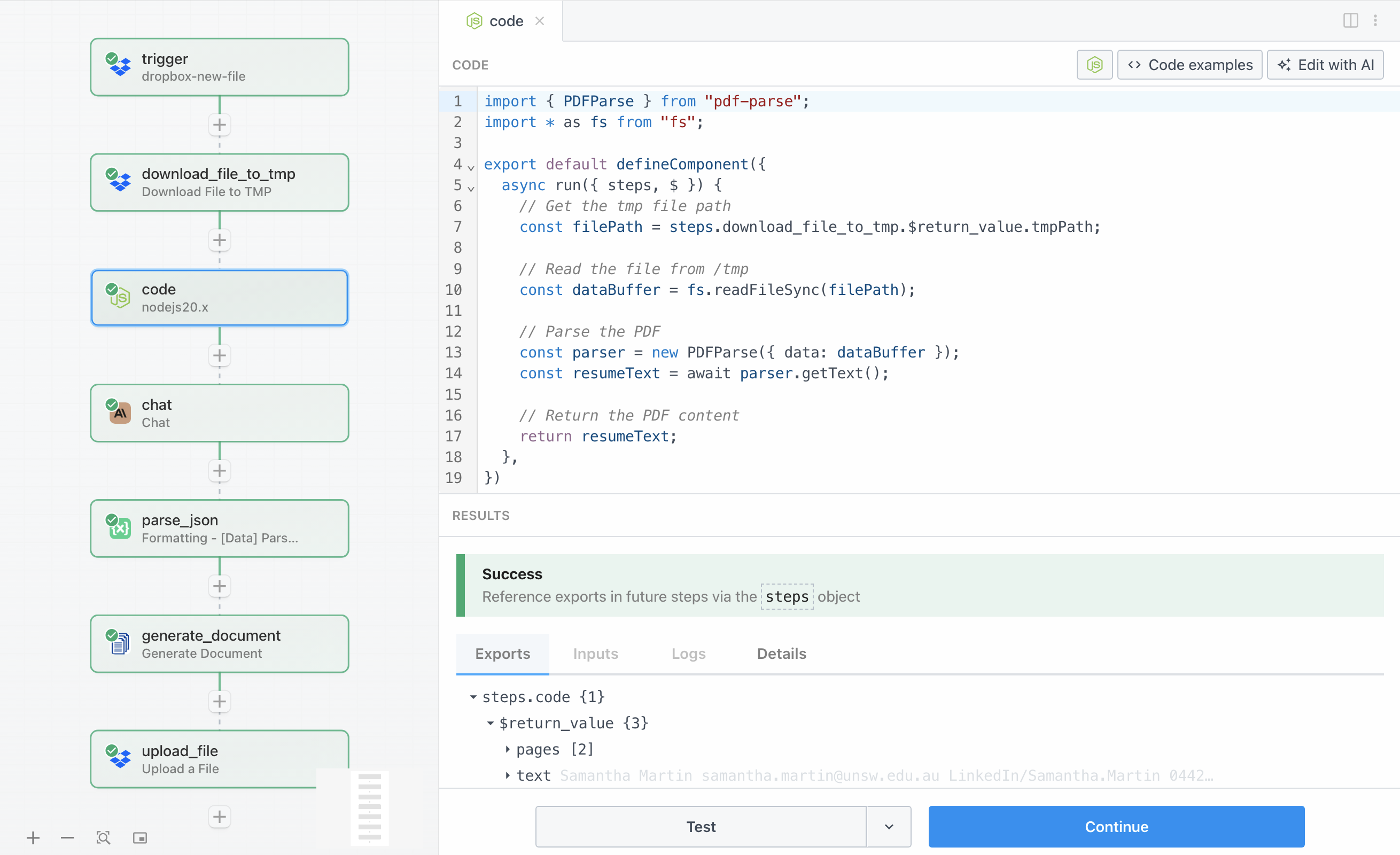
Le code lit le fichier depuis le chemin temporaire en utilisant le module intégré fs de Node.js, puis transmet le buffer du fichier à pdf-parse pour le traitement. La bibliothèque gère la complexité de l’analyse PDF et renvoie le texte extrait sous forme de chaîne de caractères.
import { PDFParse } from "pdf-parse";
import * as fs from "fs";
export default defineComponent({
async run({ steps, $ }) {
// Get the tmp file path
const filePath = steps.download_file_to_tmp.$return_value.tmpPath;
// Read the file from /tmp
const dataBuffer = fs.readFileSync(filePath);
// Parse the PDF
const parser = new PDFParse({ data: dataBuffer });
const resumeText = await parser.getText();
// Return the PDF content
return resumeText;
},
})
Le texte extrait est maintenant disponible dans resumeText et prêt à être analysé par Claude à l’étape suivante.
Analyser le CV avec Claude
C’est ici que l’intelligence intervient. L’étape Claude API envoie le texte extrait du CV à Claude AI d’Anthropic avec des instructions détaillées pour analyser le contenu et renvoyer des données structurées au format JSON. Claude examine le CV et en extrait les informations clés telles que l’expérience professionnelle, les compétences, la formation, et fournit des analyses qui nécessiteraient habituellement un examen manuel.
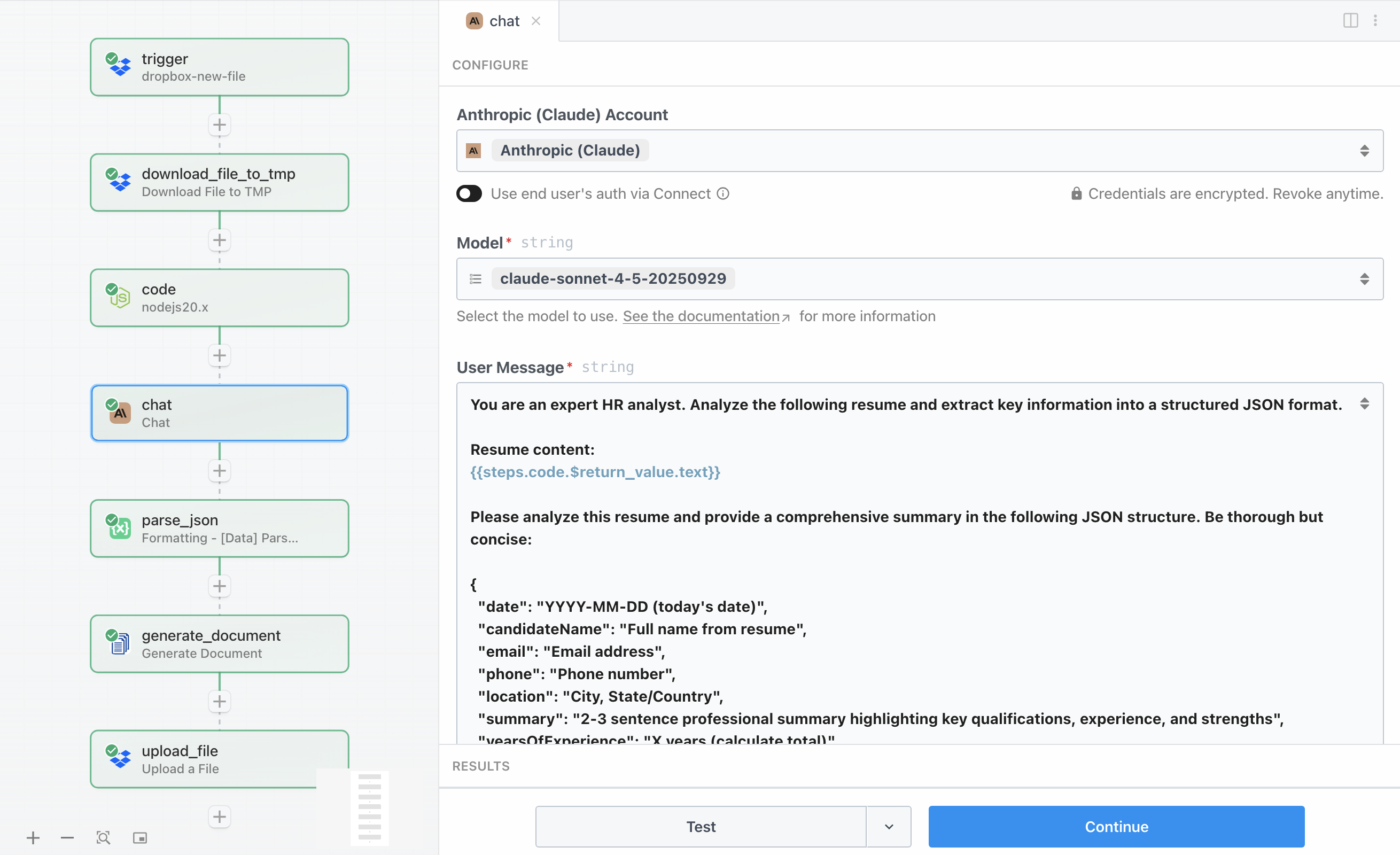
La configuration de l’action Chat with Anthropic (Claude) nécessite votre clé API Anthropic, que vous pouvez obtenir depuis votre compte Anthropic. La requête utilise le modèle claude-sonnet-4-5-20250929, qui offre un excellent équilibre entre vitesse, coût et capacité d’analyse pour cette tâche. Le paramètre Maximum Tokens to Sample est défini sur 4096, ce qui donne à Claude suffisamment d’espace pour renvoyer une analyse complète avec tous les champs dont nous avons besoin.
Le prompt est soigneusement structuré pour guider Claude dans l’extraction d’informations spécifiques et leur mise en forme en JSON valide. Voici le prompt complet qui indique à Claude quoi analyser et comment structurer la réponse :
You are an expert HR analyst. Analyze the following resume and extract key information into a structured JSON format.
Resume content:
{{steps.code.$return_value.text}}
Please analyze this resume and provide a comprehensive summary in the following JSON structure. Be thorough but concise:
{
"date": "YYYY-MM-DD (today's date)",
"candidateName": "Full name from resume",
"email": "Email address",
"phone": "Phone number",
"location": "City, State/Country",
"summary": "2-3 sentence professional summary highlighting key qualifications, experience, and strengths",
"yearsOfExperience": "X years (calculate total)",
"currentPosition": "Most recent job title",
"currentCompany": "Most recent company name",
"skills": [
"List 6-10 key technical and professional skills with proficiency levels where relevant"
],
"highestDegree": "Degree name (e.g., Bachelor of Science in Computer Science)",
"institution": "University/College name",
"fieldOfStudy": "Major/Field",
"strengths": [
"List 4-6 key strengths based on achievements, projects, and experience"
],
"recommendations": [
"List 4-5 specific interview questions or topics to explore based on their unique experience"
],
"fitScore": "Rate 1-10 based on overall qualifications and experience",
"finalNotes": "2-3 sentence overall assessment and hiring recommendation"
}
IMPORTANT INSTRUCTIONS:
- Extract all information directly from the resume
- If any field is not available in the resume, use "Not specified" or an empty array []
- For skills, include proficiency levels when they can be inferred from years of experience or explicit mentions
- Make the summary compelling but accurate
- Base the fitScore on years of experience, skill diversity, education, and career progression
- Ensure all JSON is properly formatted with no syntax errors
- Return ONLY the JSON object, no additional text or markdown formatting
CRITICAL OUTPUT REQUIREMENTS:
- Return ONLY the raw JSON object
- Do NOT wrap the JSON in markdown code blocks
- Do NOT include ```json or ``` markers
- Do NOT add any explanatory text before or after the JSON
- The response must start with { and end with }
- The entire response must be valid, parseable JSON
Claude traite le texte du CV et renvoie un objet JSON contenant toutes les informations extraites. La réponse comprend tout, des coordonnées de base à des recommandations pertinentes de questions d’entretien basées sur l’expérience unique du candidat. Ce format structuré facilite la transmission des données à DocuGenerate pour la génération de document à l’étape suivante.
Analyser la Réponse JSON
Claude renvoie son analyse sous forme de chaîne JSON, mais nous devons la convertir en un objet structuré avec lequel nous pouvons travailler dans les étapes suivantes. L’action intégrée de Pipedream Parse JSON, disponible sous Formatting → Data, gère automatiquement cette conversion.
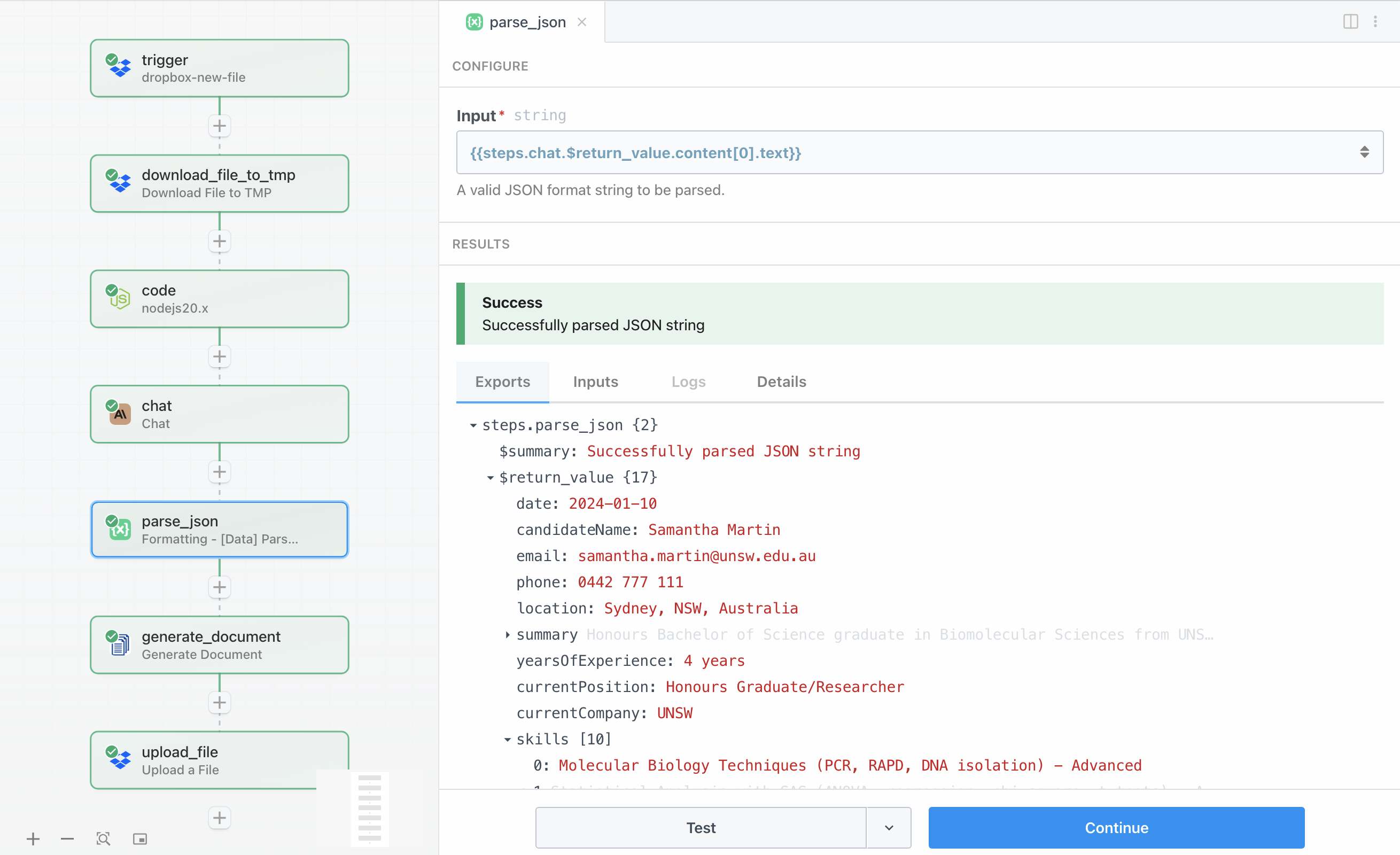
La configuration consiste simplement à prendre la réponse de Claude depuis {{steps.chat.$return_value.content[0].text}} et à l’analyser en un objet structuré. Ces données analysées deviennent disponibles pour toutes les étapes suivantes du workflow, nous permettant de référencer des champs spécifiques comme {{steps.parse_json.$return_value.candidateName}} lorsque nous en avons besoin.
Disposer de données analysées en champs individuels est particulièrement utile pour le nommage dynamique des fichiers et pour transmettre l’ensemble des données à DocuGenerate. L’objet analysé contient tous les champs définis dans notre modèle : informations du candidat, synthèse, tableau de compétences, tableau de points forts, tableau de recommandations, et l’évaluation globale.
Générer le Document de Synthèse
Avec les données analysées désormais disponibles sous forme d’objet structuré, nous sommes prêts à générer la synthèse PDF professionnelle. Cette étape utilise l’application DocuGenerate sur Pipedream pour fusionner les données avec notre modèle et créer un document mis en forme.
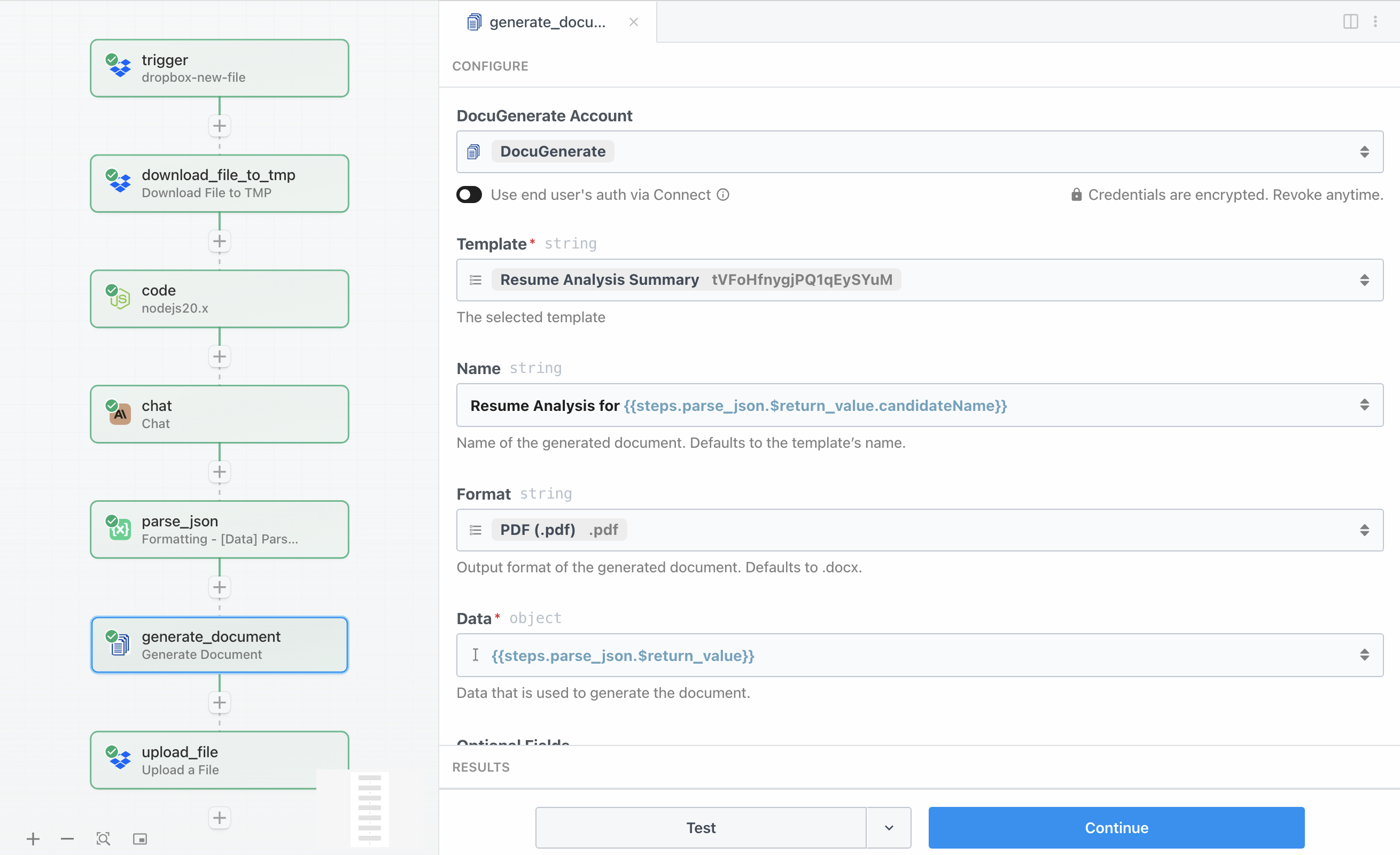
Vous aurez besoin de votre clé API DocuGenerate pour configurer une connexion, que vous pouvez trouver dans les paramètres de votre compte. La configuration de l’action inclut plusieurs paramètres importants :
- Template spécifie le modèle Resume Analysis Summary de la section de configuration
- Name utilise
Resume Analysis for {{steps.parse_json.$return_value.candidateName}} pour créer un nom de fichier dynamique basé sur le nom du candidat - Format est défini sur
PDF (.pdf) pour générer un document PDF - Data contient l’objet JSON analysé complet
{{steps.parse_json.$return_value}} provenant de Claude avec toutes les informations du candidat
L’API traite cette requête et renvoie une réponse contenant un champ document_uri, qui est une URL pointant vers le document PDF généré.
Téléverser l’Analyse sur Dropbox
La dernière étape termine le workflow en téléversant l’analyse PDF générée vers Dropbox, où votre équipe de recrutement peut y accéder. L’action Upload a File enregistre le document dans un dossier désigné, regroupant toutes les analyses de candidats au même endroit.
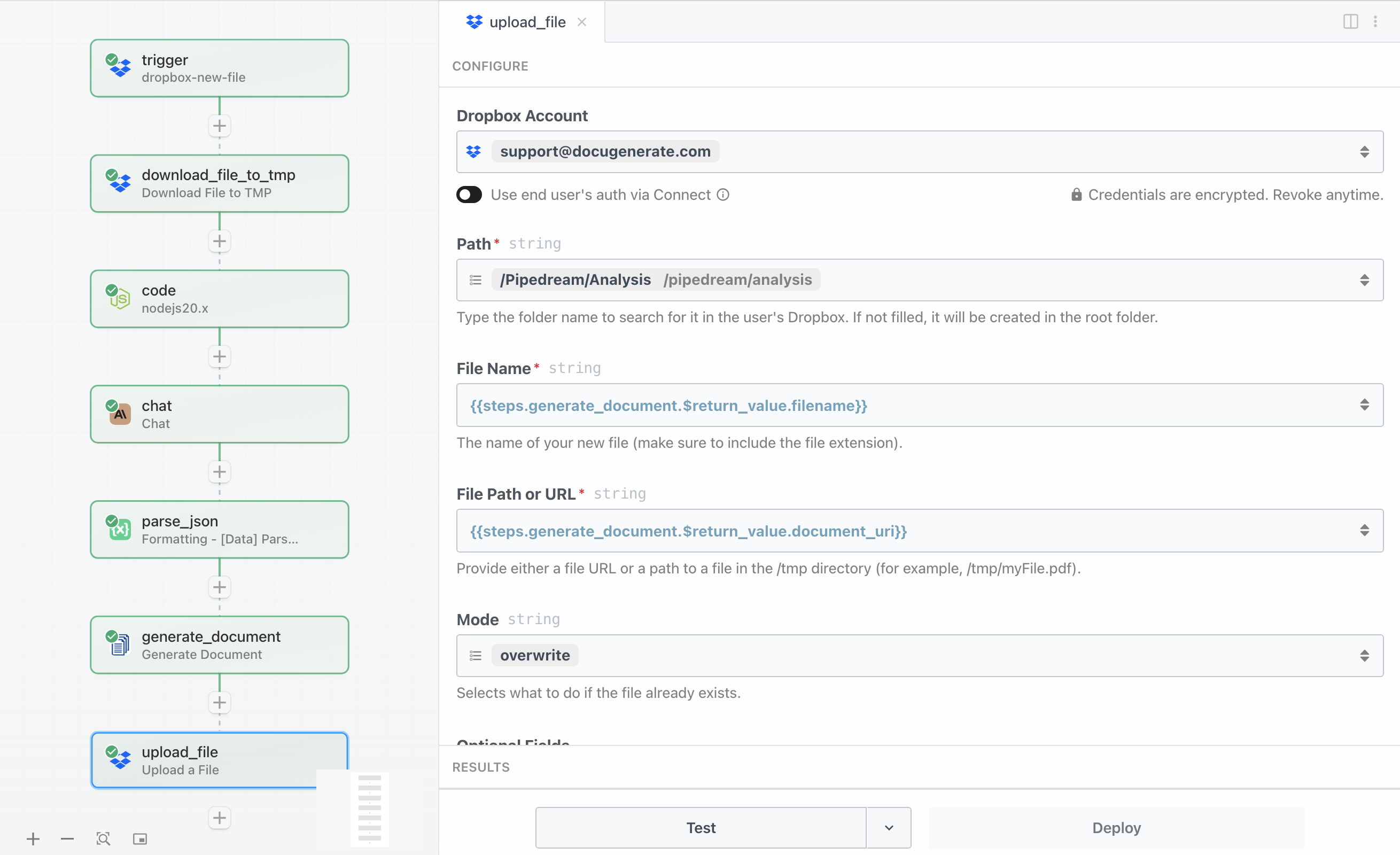
La configuration nécessite de spécifier le chemin de destination et le contenu du fichier à téléverser :
- Path spécifie le dossier de destination
/Pipedream/Analysis - File Name est défini sur
{{steps.generate_document.$return_value.filename}} comme nom de fichier du document généré - File Path or URL référence la valeur
{{steps.generate_document.$return_value.document_uri}} de l’étape précédente - Mode est défini sur
overwrite pour définir le comportement si le fichier existe déjà
Une fois téléversée, l’analyse est immédiatement disponible pour votre équipe, et vous pouvez éventuellement ajouter une étape de notification par e-mail pour alerter les responsables du recrutement lorsqu’une nouvelle synthèse de candidat est prête à être consultée.
Tester le Workflow Complet
Une fois toutes les étapes configurées, le workflow est prêt à traiter les CV automatiquement. Pour le tester, téléversez simplement un CV au format PDF dans le dossier /Pipedream/Resumes de votre Dropbox. Le workflow détectera le nouveau fichier en quelques secondes et commencera à le traiter à travers chaque étape.
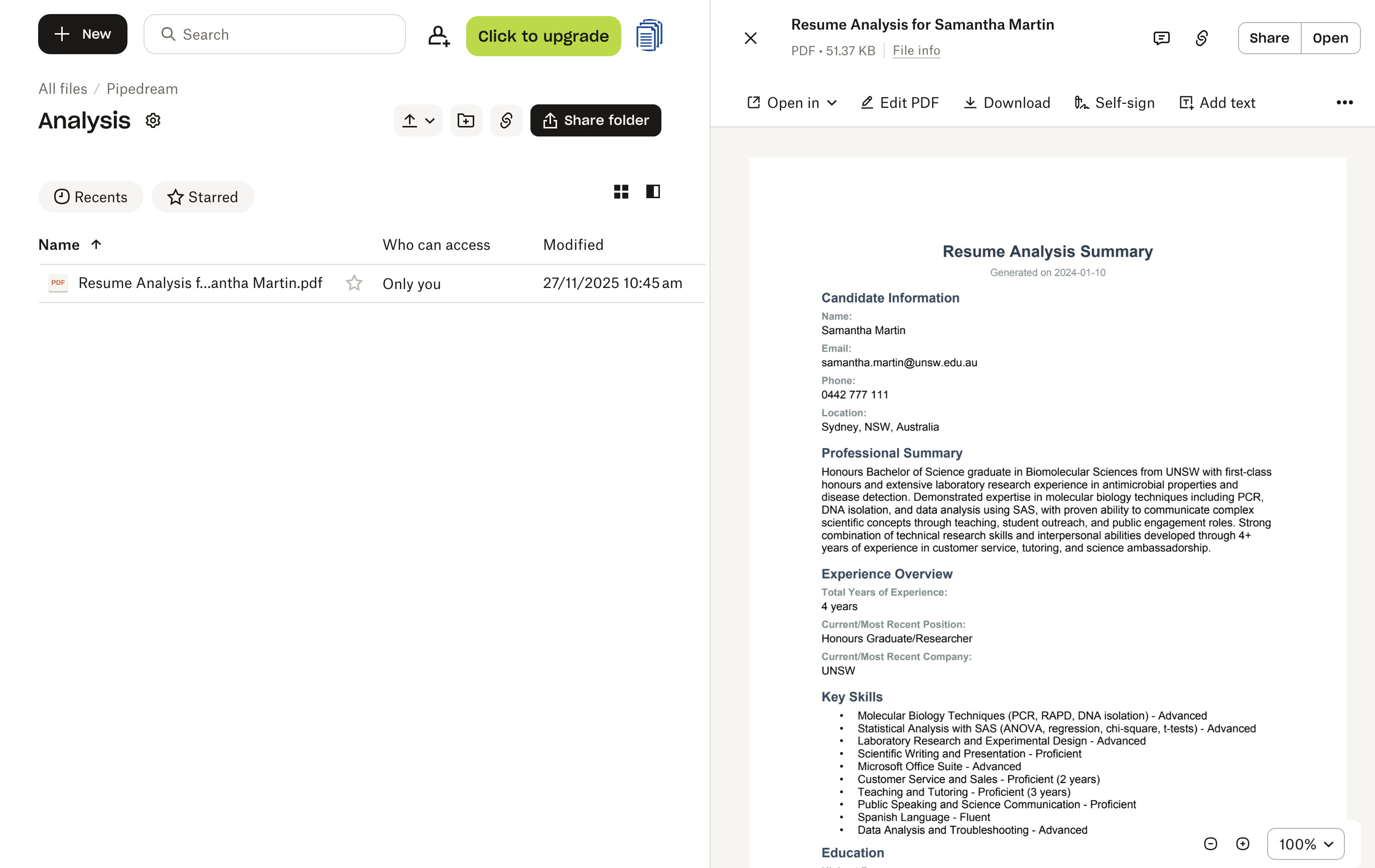
Vous pouvez suivre l’exécution en temps réel via l’interface de Pipedream, qui affiche le flux de données à travers chaque étape. Une fois terminé, vous trouverez le PDF d’analyse généré dans votre dossier /Pipedream/Analysis sur Dropbox, prêt à être consulté par votre équipe de recrutement.
Étendre le Workflow
L’analyseur de CV que nous avons créé constitue une base solide, mais il existe de nombreuses façons de l’étendre pour mieux l’adapter à votre processus de recrutement. Voici quelques améliorations pratiques que vous pourriez envisager d’ajouter pour rendre le workflow encore plus utile pour votre organisation.
Vous pourriez ajouter une étape de notification par e-mail qui alerte immédiatement les responsables du recrutement lorsqu’une nouvelle analyse de candidat est prête. Cette notification pourrait inclure les points clés de l’analyse de Claude, tels que le score d’adéquation et la synthèse professionnelle, ainsi qu’un lien direct vers le rapport PDF complet sur Dropbox. Cela évite aux responsables du recrutement de devoir constamment vérifier le dossier pour détecter de nouvelles analyses.
Une autre extension utile consiste à stocker les données JSON structurées dans une base de données ou une feuille de calcul. En ajoutant une étape qui envoie les données analysées vers Airtable, Google Sheets, ou votre système de suivi des candidatures, vous pouvez créer une base de données consultable de tous les candidats. Cela facilite le filtrage des candidats par compétences, niveau d’expérience ou score d’adéquation lorsque vous recherchez des qualifications spécifiques.
Vous pourriez également personnaliser l’analyse en fonction du poste pour lequel vous recrutez. Vous pourriez créer différents modèles pour différents rôles et utiliser le nom de fichier ou une structure de dossiers désignée pour déterminer quel modèle utiliser. Par exemple, les CV dans /Resumes/Engineering pourraient utiliser un modèle qui met l’accent sur les compétences techniques, tandis que ceux dans /Resumes/Sales pourraient se concentrer davantage sur les capacités de communication et l’expérience commerciale.
Conclusion
Créer un analyseur de CV automatisé avec Pipedream, Claude et DocuGenerate démontre comment l’IA et l’automatisation de workflows peuvent transformer des processus manuels chronophages en opérations efficaces et cohérentes. Le workflow que nous avons créé traite les CV en quelques secondes, extrait des informations pertinentes qui prendraient bien plus de temps à identifier pour un humain, et génère des rapports qui facilitent les décisions de recrutement.
Cette approche est particulièrement précieuse car elle maintient une cohérence dans l’évaluation des candidats. Chaque CV est analysé selon les mêmes critères, réduisant les biais inconscients et garantissant que tous les candidats sont évalués de manière équitable. Le format structuré des rapports d’analyse facilite également la comparaison des candidats côte à côte et l’identification des postulants les plus prometteurs pour vos postes ouverts.
Le modèle de workflow que nous avons présenté ici va au-delà de l’analyse de CV. La même approche consistant à extraire le texte de documents, à utiliser l’IA pour analyser et structurer le contenu, puis à générer des rapports mis en forme peut être appliquée à de nombreux autres scénarios de traitement documentaire. Que vous analysiez des contrats, traitiez des retours clients, ou extrayiez des données de documents de recherche, le workflow principal reste similaire, avec des ajustements du prompt d’analyse et du modèle de sortie.
Ressources